Classics in the Age of Wikipedia: Creating, Sharing and Accessing Information in a Global, Networked Environment
Lecture Series at the XXI Simposio Nacional de Estudios Clásicios, Santa Fe, Argentina (Sept. 22-24, 2010)
David Bamman
The Perseus Project, Tufts University
I. Introduction to Computational Methods for Classical Philology
From the Gutenberg Press to the Internet, one of the biggest impacts of the use of information technologies within the sphere of Classical Studies has been in providing ever-increasing levels of access - not simply physical access to the primary texts of the Classical tradition, but intellectual access as well.
For traditional textual scholars and Classical philologists, the availability of texts online is a first big step - we can now look at highly detailed images of the Venetus A manuscript of Homer's Iliad without having to go to Venice, or use the Internet Archive to read an 1891 Teubner edition of Sallust without going to our university libraries.
The related fields of computational linguistics and natural language processing (NLP) are pushing this innovation even further by helping to provide increased intellectual access to these cultural heritage materials as well. For early learners of Greek and Latin, the methods of automatic linguistic analysis and machine translation help to lower the barrier of entry to interacting with primary source texts. For advanced researchers, computational methods not only expedite the traditional research that's being done already, but also help uncover new information about the Greco-Roman world and its reception throughout the written record of history.
This talk will provide a general introduction to computational methods for Classicists, with a special focus on the digital resources and technologies that traditional scholars can use.
II. Linguistic Annotation of Classical Texts
One of the biggest contributions that traditional scholars can make to the field of computational philology is leveraging their expert knowledge in Greek and Latin to create linguistically annotated texts, and then publishing those texts for the entire community to use. This annotation can take several forms, including encoding the citation structure (like chapter and section breaks) in a digital edition, disambiguating the people and places mentioned in the text (e.g., annotating a given instance of "Alexander" in a text as Alexander the Great and not as Paris, the son of Priam), and marking the explicit syntactic relationship for each word in a sentence of Vergil.
This level of annotation does not require a sophisticated technological background - in many cases, it simply requires navigating the web. The data created by such annotation, however, is tremendously powerful: it can provide the training material for computational methods, and it can also provide a quantified foundation on which to explore many traditional questions - if we have a large collection of syntactic analyses for Latin poetry, for example, we can automatically identify rhetorical devices (such as hyperbaton) that involve the interaction between linear word order and syntax.
In all of this work, collaboration between different groups (and across languages) is crucial. Since many annotation tasks are performed with a strictly controlled vocabulary, the only language proficiency required is that of Greek or Latin - enabling students and researchers who are native speakers of English, Spanish, Arabic or Chinese to work together.
In this talk, I will illustrate several varieties of annotation tasks for Greek and Latin texts, focusing especially on 1) the creation of new digital editions; 2) disambiguating people and places; and 3) creating syntactic analyses (or "treebanks") of texts. One goal of this talk will be an outline of the practical steps required for researchers to immediately begin this work themselves.
III. Mapping the Greek and Latin Genome: A Workshop on Treebanking
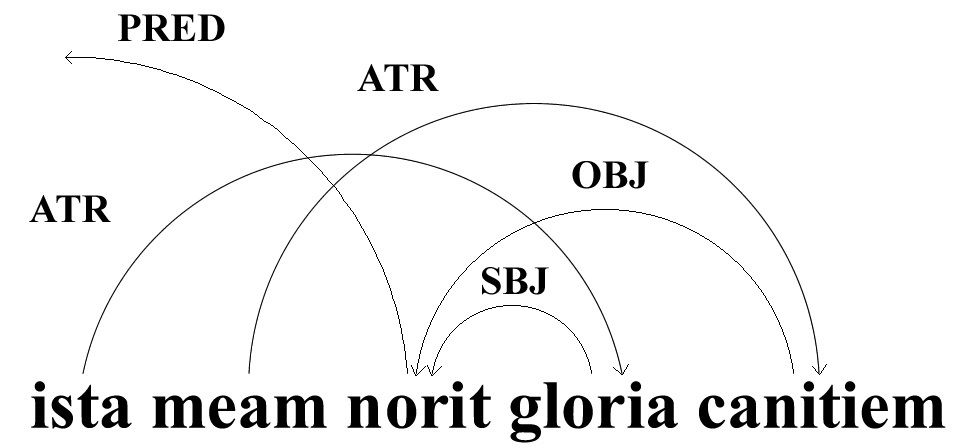
Treebanking is a form of linguistic annotation that involves marking the explicit syntactic relation for every word in a sentence (e.g., annotating the subject of the verb, its objects, which adjectives modify which nouns), as in the following annotation of ista meam norit gloria canitiem ("that glory will know my old age") from Propertius 1.8.
|
Treebanks exist for many modern languages (where they provide valuable training material for automatic parsers) but several are arising for historical languages as well, including those for Old English, Middle English, Early Modern English, Medieval Portuguese, Classical Chinese, Ugaritic, and our own work on the Ancient Greek and Latin Dependency Treebanks. Over the past three years and with the help of over 200 students, scholars and university classes from across the world, we have published almost 250,000 words of treebanked texts from a variety of authors (Homer, Hesiod, Aeschylus, Caesar, Cicero, Jerome, Ovid, Petronius, Propertius, Sallust and Vergil). This talk will give a working introduction to this kind of syntactic annotation, including an overview of the grammatical style, the community of treebankers, and a tutorial on the online annotation environment. The goal of this workshop is to provide the audience with the basic skills needed to undertake treebanking of any Greek or Latin text themselves.